Resuscitating Dead Data with Unified Laboratory Intelligence
LISTED UNDER:
A recent survey from the International Data Corporation (IDC) suggests that knowledge workers spend 15-35% of their time searching for information. A previous study by the same firm estimated that an enterprise with 1,000 knowledge workers loses a minimum of $6 million a year in the time workers spend searching for, and not finding, needed information.1 These types of issues are very relevant in the pharmaceutical and chemical industries. In these environments, many laboratory experiments represent expensive, time-consuming repeats of previous experiments, simply because the data cannot be found or, if found, cannot be re-used. This major inefficiency that can significantly increase the time and cost of chemical R&D can be referred to as the traditional one-and-done data life cycle.
For example, in a synthetic chemistry workflow this life cycle will begin with a proposed chemical structure or reaction schema. Data is acquired to confirm the identity of starting materials as well as the end product. A series of experiments may be run to provide specific knowledge about a specific characteristic of the structure. The resultant data is often displayed in a plot or graph (LC-MS and/or 1H NMR), which is usually converted into an unstructured format (raw data from disparate instrumentation, PDF, image, etc.). As a result, while the scientist gains insight from the experiment at that given time, the knowledge and relationship between the chemical structure and analytical data acquired is essentially frozen, cannot be re-used, and hence is considered ‘dead’ data.
Dead Data
‘Dead’ data is a term used to describe data that is unstructured and located in heterogeneous silos in different data formats. IDC claims that 80% of new information growth is unstructured content, with 90% of that being unmanaged in disparate data silos.2 In these environments the data becomes nearly impossible to search and retrieve and thus no longer useful beyond it’s initial specific purpose. While experiment repetition can generate multiple instances of discrete knowledge, the one-and-done life cycle rarely, if ever, provides a knowledge source to allow other scientists to garner insights. When information is essentially frozen as ‘dead’ data, scientists can no longer re-process, re-analyze, or manipulate the data for different purposes, squandering the opportunity to translate these forms of information and knowledge into corporate intelligence.
In order to leverage these instances of discrete knowledge from the vast amounts of data being generated in the lab, new approaches to make data ‘live’, digital, standardized and easily accessible in a reusable format needs to become a priority. Unified Laboratory Intelligence (ULI)3 introduces a new technology framework that requires the collection and conversion of heterogeneous raw and processed data from different instruments within and across laboratories to homogeneous structured data with metadata. More importantly, it requires a platform to store unified chemical, structural, and analytical information as ‘live’ data in order to capture a scientist’s interpretation and knowledge. This ultimately enables organizations the ability to build analytical data content (what) with chemical context (why), which is the foundation for creating intelligence-from-information. Within a ULI framework, all of this analytical content acquired from chromatography, spectrometry, spectroscopy, and other “proof” rich techniques is indexed and stored as ‘live’ data and brought together within the context of an experiment, existing process, or an evolving project. Over time, the ‘live’ database becomes the locus of continual, expansive analysis by scientists in different disciplines across the R&D enterprise. They can search, retrieve, and re-analyze information to generate new knowledge and each analysis cycle adds new knowledge back to the database again and again, project-after project. The continuous accumulation of knowledge, from multiple analyses over successive projects, creates a platform of corporate intelligence for better communication, collaboration, and decision-making throughout research and development.
For example, the identification of impurities or contaminants from previous studies that arise during product development may be fast-tracked without having to conduct additional laboratory experiments, which can substantially reduce costs, shorten production delays, and help accelerate development. Collectively, the elements that comprise the ULI framework can add significant value by fully utilizing retained knowledge to maximize the probability of positive outcomes and avoid potentially negative ones.
Unifying the Data
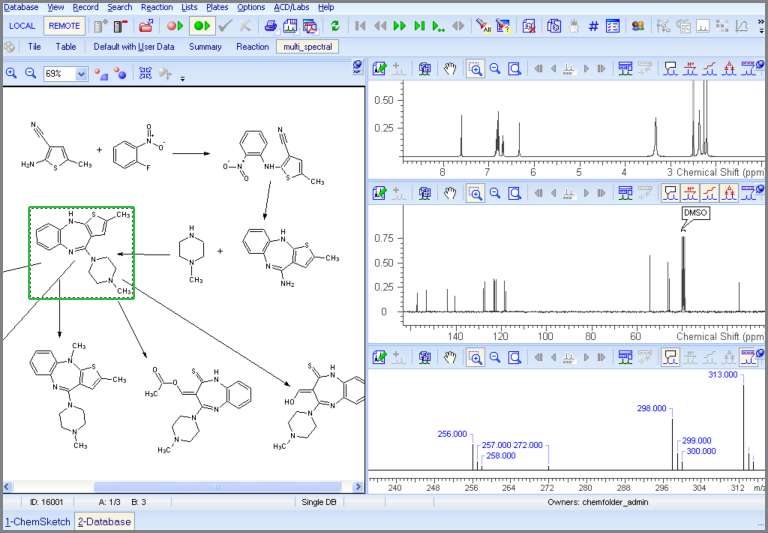
ACD/Spectrus is a scalable platform commercialized by ACD/Labs, Inc. that can help organizations implement a ULI framework and resuscitate their ‘dead’ data. Figure 1 illustrates how this platform can be used to capture the life cycle of impurities throughout a drug development project. As an Active Pharmaceutical Ingredient (API) makes its way through early to late stage development, the synthetic route along with the chromatographic methods for purification can change drastically. As a result the the number of impurity and degradation products that need to be identified and characterized quickly grows, as does the volume of data acquired. This process today, is generally managed through a series of paper-based reports with references to dead data in unstructured formats. The ACD/Spectrus platform can unify the ‘live’ analytical data from disparate instrument formats and help the process development group put it into the context of the synthetic route of the API as it evolves through the course of time. This can provide easy and quick access to ‘live’ data in the context of a project for quick comparisons to dramatically improve the process of impurity identification, elucidation, and characterization. It also provides a contextual dashboard that enables better collaboration from the multi-disciplinary teams involved in a late stage development project.
The ACD/Spectrus platform should not be viewed as a replacement to existing informatics technologies (ELN, LIMS, SDMS, etc.) but instead a complement that adds unique value by capturing and leveraging knowledge from ‘live’ analytical data. A 2011 survey of R&D professionals revealed that, “88% of R&D organizations lack adequate systems to automatically collect data for reporting, analysis, and decision-making.”4 Obviously a significant gap remains and Unified Laboratory Intelligence is a new approach to help address this.
References
1. Susan Feldman and Chris Sherman, The High Cost of Not Finding Information, IDC #29127, April 2003
2. IDC, The Digital Universe Decade- Are you Ready?, May 2010
3. Ryan Sasaki and Bruce Pharr, Unified Laboratory Intelligence White Paper, February 2013.
4. R&D Informatics: Are you ready for 2012?, http://blog.idbs.com/2011/10/18/rd-informatics-–-are-you-ready-for-2012/, IDBS (October 18, 2024).